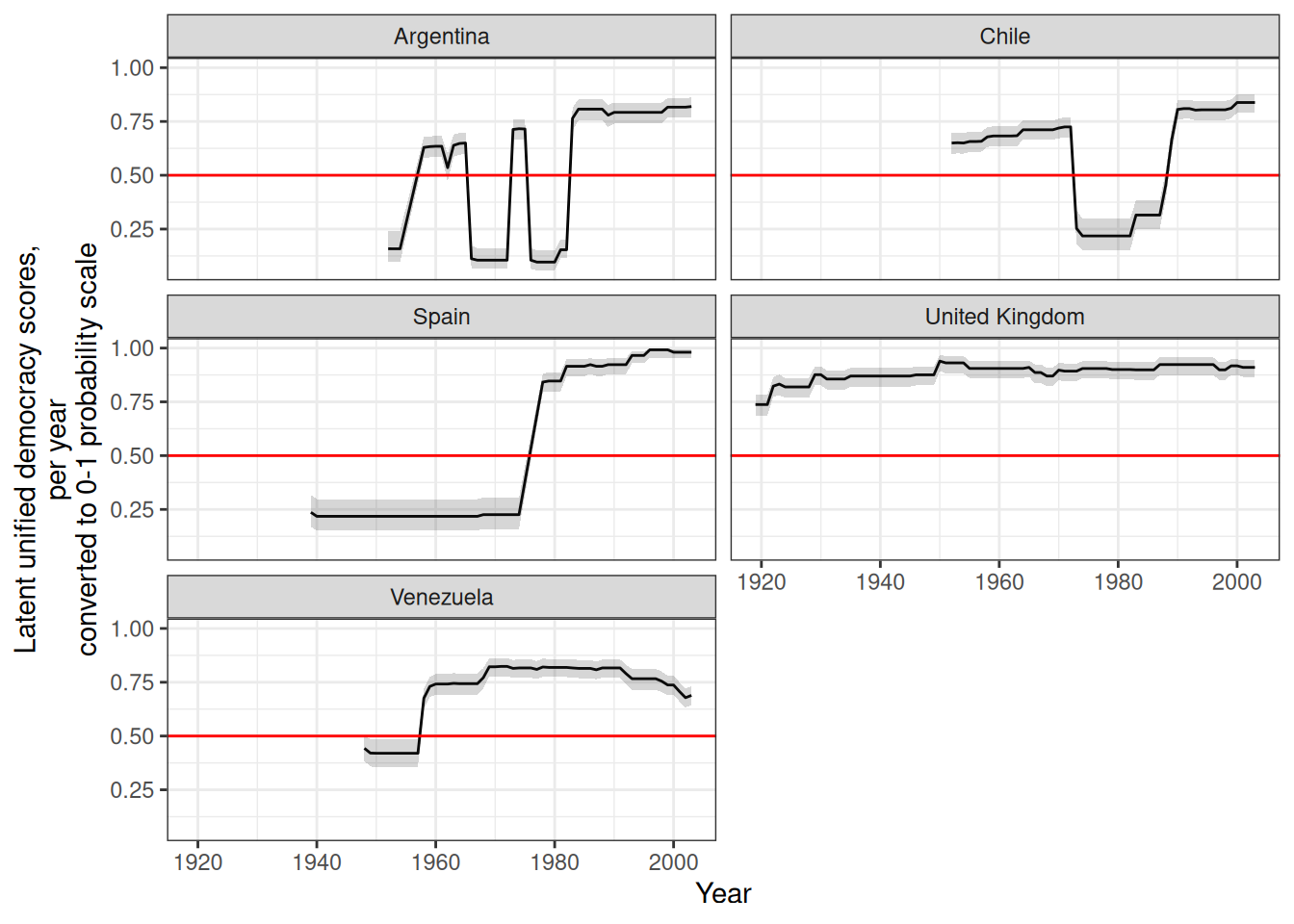
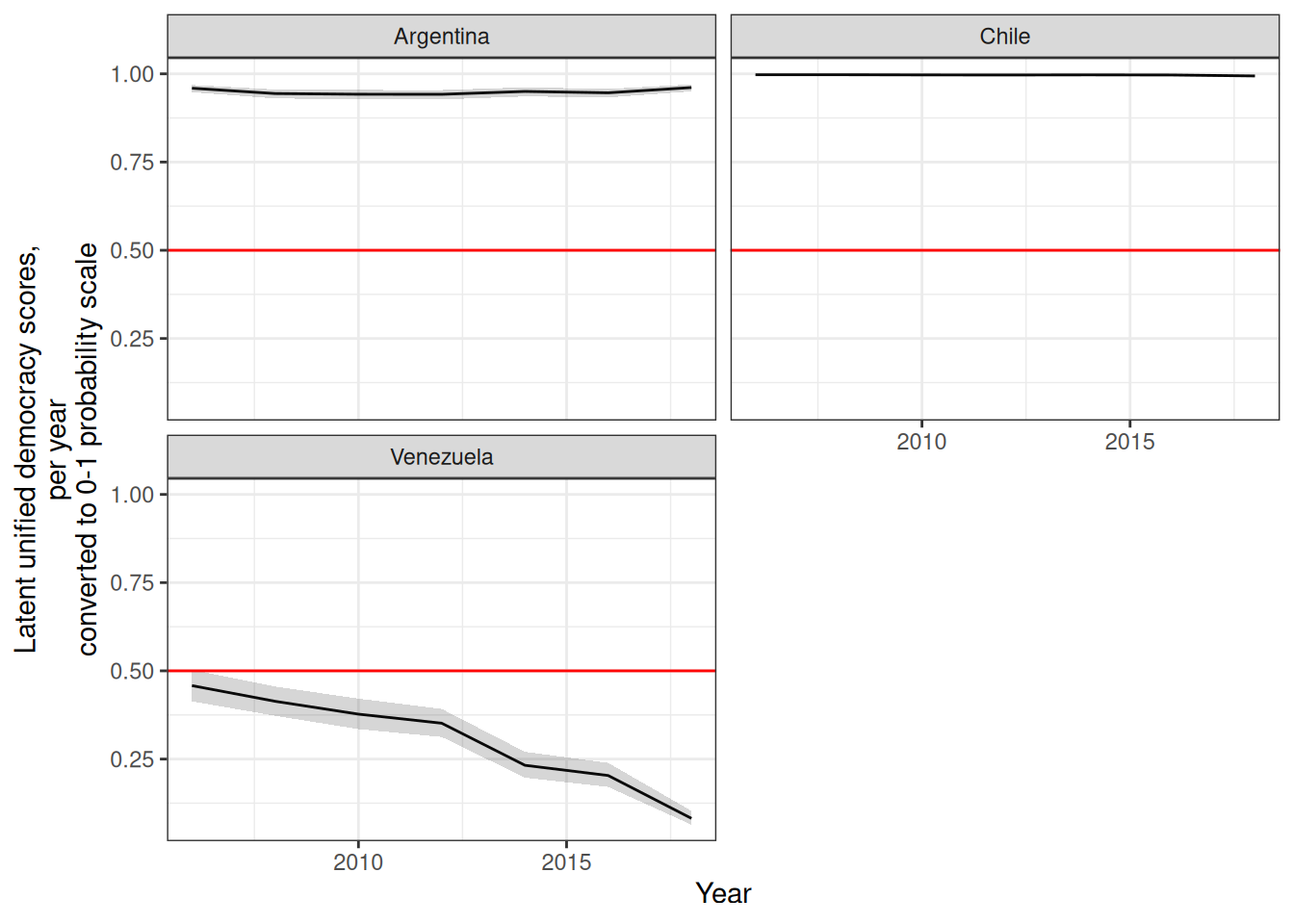
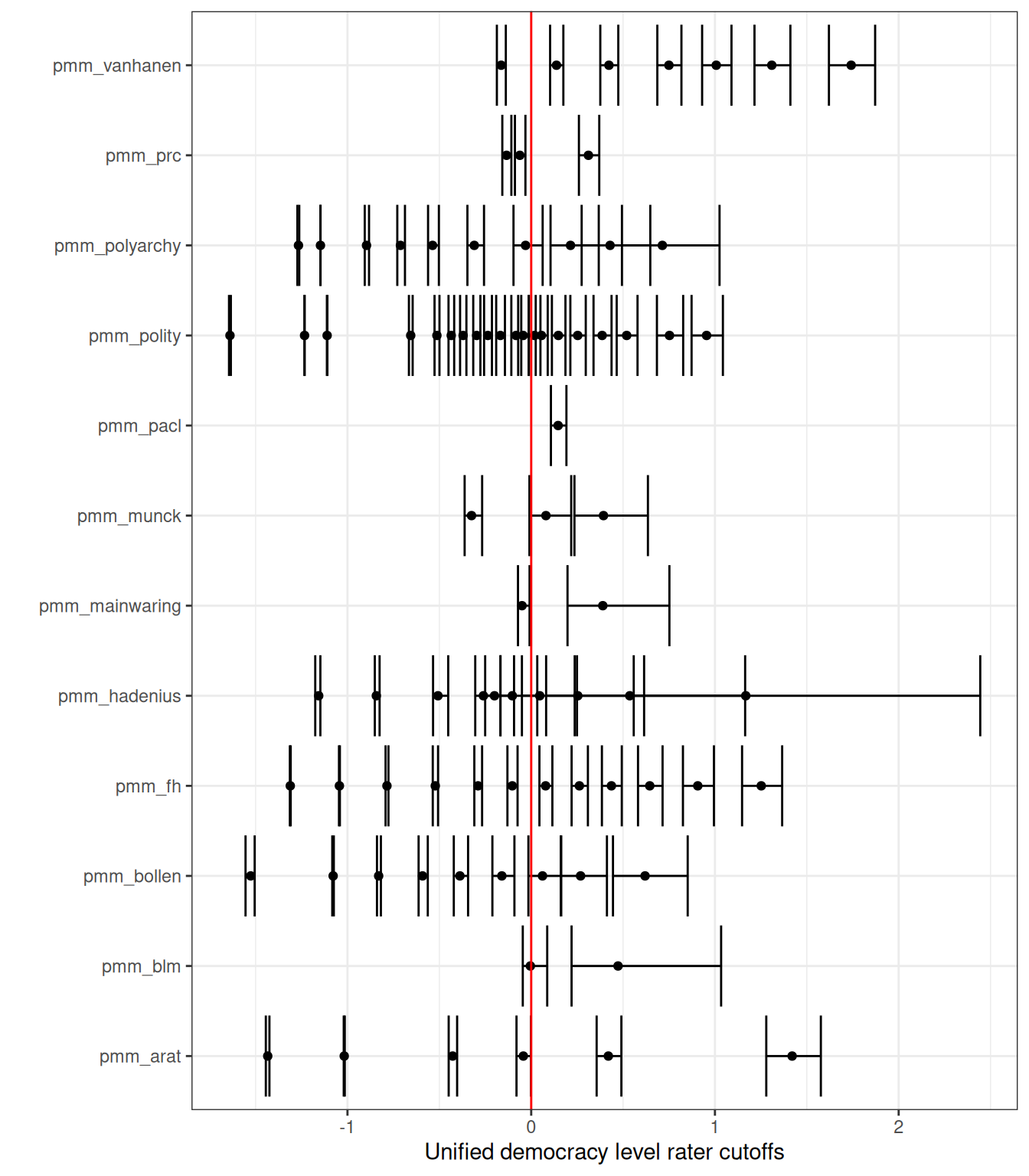
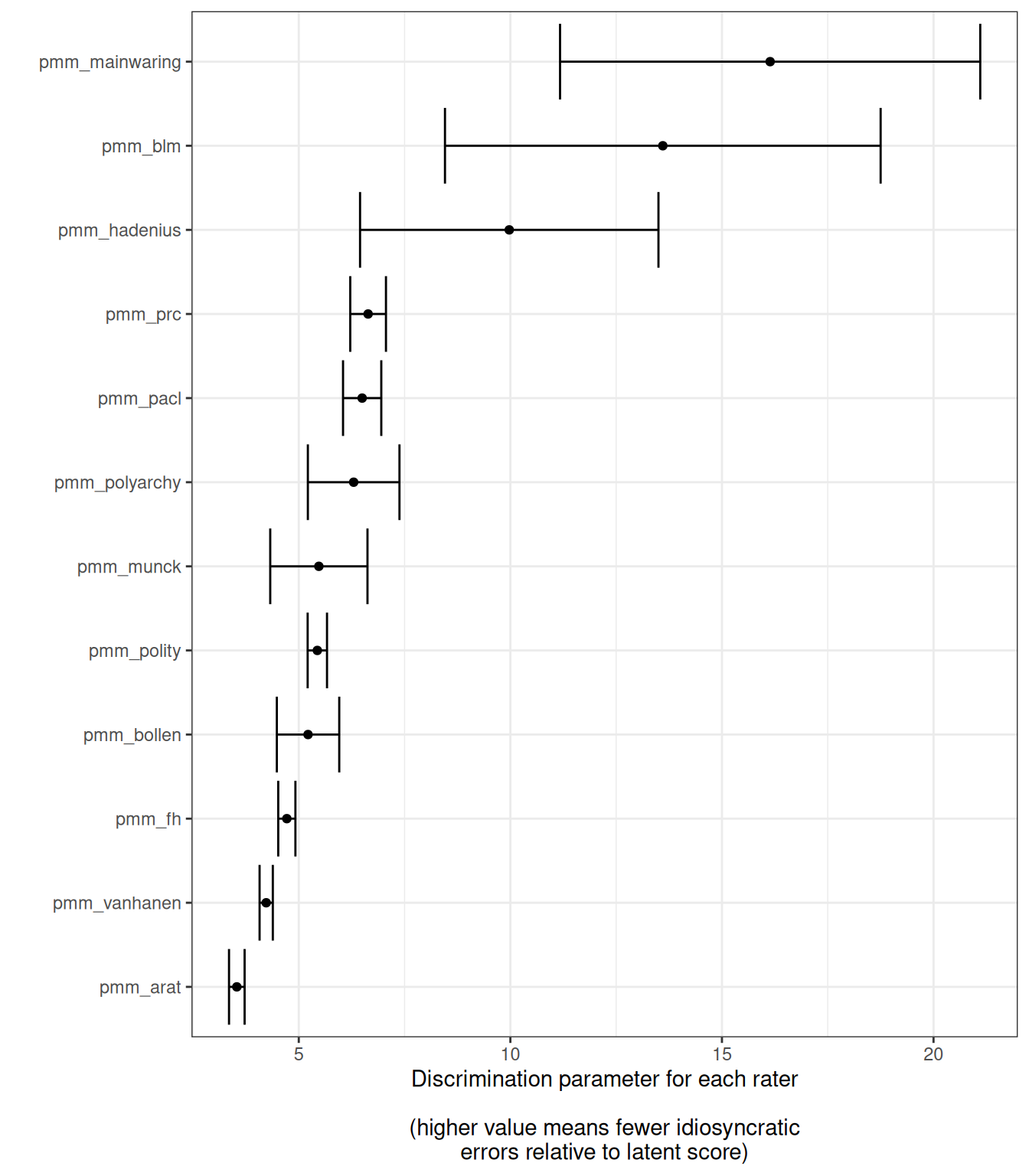
Acemoglu, Daron, Suresh Naidu, Pascual Restrepo, and James A. Robinson. 2019.
“Democracy Does Cause Growth.” Journal of Political Economy 127(1): 47–100. doi:
10.1086/700936.
Anckar, Carsten, and Cecilia Fredriksson. 2018.
“Classifying Political Regimes 1800–2016: A Typology and a New Dataset.” European Political Science 18(1): 84–96. doi:
10.1057/s41304-018-0149-8.
Arat, Zehra F. 1991. Democracy and Human Rights in Developing Countries. Boulder: Lynne Rienner Publishers.
Bell, Curtis. 2016.
“The Rulers, Elections, and Irregular Governance Dataset (REIGN).” https://oefdatascience.github.io/REIGN.github.io/.
Bertelsmann Stiftung. 2026.
Transformation Index BTI 2026: Governance in International Comparison. Gütersloh: Bertelsmann Stiftung. Report.
https://www.bertelsmann-stiftung.de/en/publications/publication/did/transformation-index-bti-2026.
Boix, Carles, Michael Miller, and Sebastian Rosato. 2012.
“A Complete Data Set of Political Regimes, 1800–2007.” Comparative Political Studies 46(12): 1523–54. doi:
10.1177/0010414012463905.
Bollen, Kenneth A. 2001.
“Cross-National Indicators of Liberal Democracy, 1950-1990.” doi:
10.3886/ICPSR02532.v2.
Bowman, Kirk, Fabrice Lehoucq, and James Mahoney. 2005.
“Measuring Political Democracy: Case Expertise, Data Adequacy, and Central America.” Comparative Political Studies 38(8): 939–70. doi:
10.1177/0010414005277083.
Chalmers, R. Philip. 2012.
“Mirt: A Multidimensional Item Response Theory Package for the R Environment.” Journal of Statistical Software 48(6): 1–29. doi:
10.18637/jss.v048.i06.
Cheibub, José Antonio, Jennifer Gandhi, and James Raymond Vreeland. 2009.
“Democracy and Dictatorship Revisited.” Public Choice 143(1–2): 67–101. doi:
10.1007/s11127-009-9491-2.
Coppedge, Michael, Angel Alvarez, and Claudia Maldonado. 2008.
“Two Persistent Dimensions of Democracy: Contestation and Inclusiveness.” The journal of politics 70(03): 632–47. doi:
10.1017/S0022381608080663.
Coppedge, Michael, John Gerring, Carl Henrik Knutsen, Staffan I. Lindberg, Jan Teorell, David Altman, Fabio Angiolillo, et al. 2026.
V-Dem Codebook V16. Varieties of Democracy (V-Dem) Project. Report.
https://www.v-dem.net/documents/70/codebook_v16.pdf.
Coppedge, Michael, and Wolfgang H. Reinicke. 1990. “Measuring Polyarchy.” Studies in Comparative International Development 25(1): 51–72.
Doorenspleet, Renske. 2000.
“Reassessing the Three Waves of Democratization.” World Politics 52(03): 384–406. doi:
10.1017/S0043887100016580.
Freedom House. 2025. Freedom in the World 2025: The Uphill Battle to Safeguard Rights. Freedom House.
Gasiorowski, Mark. 1996.
“An Overview of the Political Regime Change Dataset.” Comparative Political Studies 29(4): 469–83. doi:
10.1177/0010414096029004004.
Geddes, Barbara, Joseph Wright, and Erica Frantz. 2014.
“Autocratic Breakdown and Regime Transitions: A New Data Set.” Perspectives on Politics 12(1): 313–31. doi:
10.1017/S1537592714000851.
Goldstone, Jack, Robert Bates, David Epstein, Ted Gurr, Michael Lustik, Monty Marshall, Jay Ulfelder, and Mark Woodward. 2010.
“A Global Model for Forecasting Political Instability.” American Journal of Political Science 54(1): 190–208. doi:
10.1111/j.1540-5907.2009.00426.x.
Gründler, Klaus, and Tommy Krieger. 2021/05/17/.
“Using Machine Learning for Measuring Democracy: A Practitioners Guide and a New Updated Dataset for 186 Countries from 1919 to 2019.” European Journal of Political Economy: 102047. doi:
10.1016/j.ejpoleco.2021.102047.
Gründler, Klaus, and Tommy Krieger. 2016.
“Democracy and Growth: Evidence from a Machine Learning Indicator.” European Journal of Political Economy 45: 85–107. doi:
10.1016/j.ejpoleco.2016.05.005.
Gründler, Klaus, and Tommy Krieger. 2018.
Machine Learning Indices, Political Institutions, and Economic Development. CESifo Group Munich. Report.
https://dx.doi.org/10.2139/ssrn.3171982.
Hadenius, Axel. 1992. Democracy and Development. New York: Cambridge University Press.
Hsu, Sara. 2008. “The Effect of Political Regimes on Inequality, 1963-2002.” UTIP Working Paper (53).
Kailitz, Steffen. 2013. “Classifying Political Regimes Revisited: Legitimation and Durability.” Democratization 20(1): 39–60.
Kailitz, Steffen. 2026. “Varieties of Political Regimes (Va-PoReg). Dataset. Version 3.2.”
Kaufmann, Daniel, and Aart Kraay. 2020.
“Worldwide Governance Indicators.” http://www.govindicators.org.
Magaloni, Beatriz, Jonathan Chu, and Eric Min. 2013.
“Autocracies of the World, 1950-2012 (Version 1.0).” https://dx.doi.org/10.2139/ssrn.4346003.
Mainwaring, Scott, Aníbal Pérez-Liñán, and Daniel Brinks. 2014.
“Political Regimes in Latin America, 1900-2007 (with Daniel Brinks).” In
Democracies and Dictatorships in Latin America: Emergence, Survival, and Fall, New York: Cambridge University Press.
https://web.archive.org/web/20120119050029/http://kellogg.nd.edu/scottmainwaring/Political_Regimes.pdf.
Márquez, Xavier. 2016.
“A Quick Method for Extending the Unified Democracy Scores.” Available at SSRN 2753830. doi:
10.2139/ssrn.2753830.
Marshall, Monty G., and Ted Robert Gurr. 2020. Polity 5: Political Regime Characteristics and Transitions, 1800-2018. Dataset Users’ Manual. Center for Systemic Peace. manual.
Marshall, Monty G., Ted Robert Gurr, and Keith Jaggers. 2019. Polity IV Project: Political Regime Characteristics and Transitions, 1800-2018. Dataset Users’ Manual. Center for Systemic Peace. manual.
Moon, Bruce E., Jennifer Harvey Birdsall, Sylvia Ciesluk, Lauren M. Garlett, Joshua J. Hermias, Elizabeth Mendenhall, Patrick D. Schmid, and Wai Hong Wong. 2006.
“Voting Counts: Participation in the Measurement of Democracy.” Studies in Comparative International Development 41(2): 3–32. doi:
10.1007/BF02686309.
Munck, Gerardo. 2009. Measuring Democracy: A Bridge Between Scholarship and Politics. Baltimore: The Johns Hopkins University Press.
Pemstein, Daniel, Stephen A. Meserve, and James Melton. 2013.
“Replication Data for: Democratic Compromise: A Latent Variable Analysis of Ten Measures of Regime Type.” doi:
10.7910/DVN/WWYOHU.
Pemstein, Daniel, Stephen Meserve, and James Melton. 2010.
“Democratic Compromise: A Latent Variable Analysis of Ten Measures of Regime Type.” Political Analysis 18(4): 426–49. doi:
10.1093/pan/mpq020.
Przeworski, Adam. 2013.
“Political Institutions and Political Events (PIPE) Data Set.” https://sites.google.com/a/nyu.edu/adam-przeworski/home/data.
Reich, G. 2002.
“Categorizing Political Regimes: New Data for Old Problems.” Democratization 9(4): 1–24. doi:
10.1080/714000289.
Skaaning, Svend-Erik, John Gerring, and Henrikas Bartusevičius. 2015.
“A Lexical Index of Electoral Democracy.” Comparative Political Studies 48(12): 1491–1525. doi:
10.1177/0010414015581050.
Svolik, Milan. 2012. The Politics of Authoritarian Rule. Cambridge; New York: Cambridge University Press.
Taylor, Sean J., and Jay Ulfelder. 2015.
“A Measurement Error Model of Dichotomous Democracy Status.” Available at SSRN. doi:
10.2139/ssrn.2726962.
The Economist Intelligence Unit. 2026.
Democracy Index 2025: Democracy Stabilises After Eight Years of Decline. London: Economist Intelligence Unit. Report.
https://www.eiu.com/n/campaigns/democracy-index-2025/.
Ulfelder, Jay. 2012.
“Democracy/Autocracy Data Set.” doi:
10.7910/DVN/M11WFC.
Vanhanen, Tatu. 2019.
“Measures of Democracy 1810-2018 (Dataset). Version 8.0 (2019-06-17).” https://urn.fi/urn:nbn:fi:fsd:T-FSD1289.
Wahman, Michael, Jan Teorell, and Axel Hadenius. 2013.
“Authoritarian Regime Types Revisited: Updated Data in Comparative Perspective.” Contemporary Politics 19(1): 19–34. doi:
10.1080/13569775.2013.773200.